Search for what is work, and you will see a onebox with a Google Answers icon and the “display” or source URL as wordnetweb.princeton.edu/perl/webwn.
Follow normal search behavior and click the top link or the image in the onebox and you will go to a Google scraper page, http://www.google.com/search?hl=en&defl=en&q=define:work instead of going to the Princeton.edu page. In order to view the results on the source page, you would need to click the smaller link that says “Definition in context”.
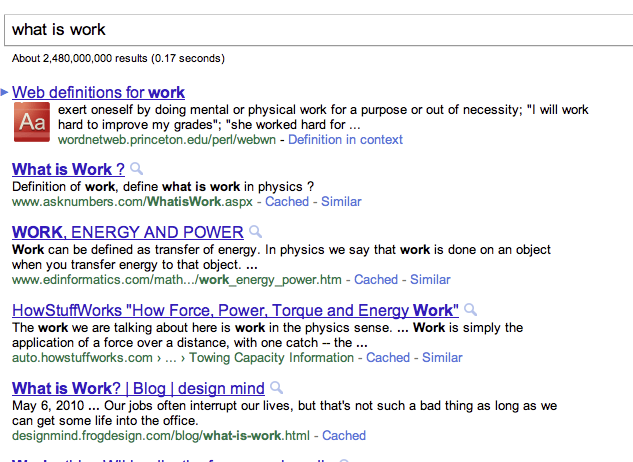
Princeton likely doesn’t care that Google is stealing traffic from WordNet, http://wordnet.princeton.edu/, but other publishers need to know that Google is running its own scraper sites and putting 3rd party content at the top of the page and using it to divert traffic away from the source.
Thanks to David Bayer of Data Banq for pointing this out.
They’re not scraping. Wordnet is a lexical database can be used by commercial companies, free of charge, so long as proper citation is given: http://wordnet.princeton.edu/wordnet/publications/#Citing_WordNet
Ben
Look at the difference between the display URL and where Google takes you for the result. The fact that Google is hosting this content instead of linking to an external source is quite unusual. Add to it the fact that Google is showing this in the OneBox and content publishers have reason to be concerned.